
Introduction
Machine learning models are becoming increasingly complex and sophisticated, with the aim of achieving high accuracy on complex tasks. However, with the increasing complexity comes the drawback of large computational resources and memory requirements. Knowledge distillation provides a solution to this problem by allowing us to transfer the knowledge from a large, more complex model to a smaller, more computationally efficient one.
What is Knowledge Distillation?
Knowledge distillation is the process of training a smaller model to imitate the behavior of a larger, more complex model. The smaller model, also known as the student model, is trained on the outputs of the larger, more complex model, also known as the teacher model. The student model learns to replicate the outputs of the teacher model, in effect, acquiring its knowledge.
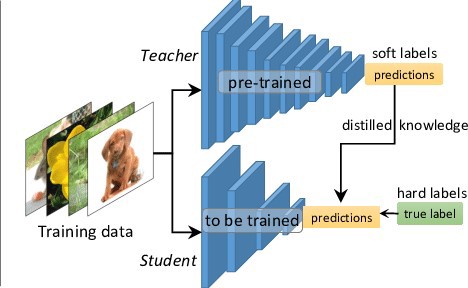
Difference between Transfer Learning and Knowledge Distillation
It is important to note that while knowledge distillation and transfer learning both aim to transfer knowledge from one model to another, they are not the same thing.
In transfer learning, a pre-trained model is fine-tuned on a new task with a different dataset. The pre-trained model already has knowledge of general features and patterns learned from the original task, which can be transferred and adapted to the new task.
In contrast, knowledge distillation is a process of training a smaller model to imitate the behavior of a larger, more complex model. The knowledge transferred from the larger model is specific to the task it was trained on and does not take into account any general features or patterns.
Benefits of Knowledge Distillation
-
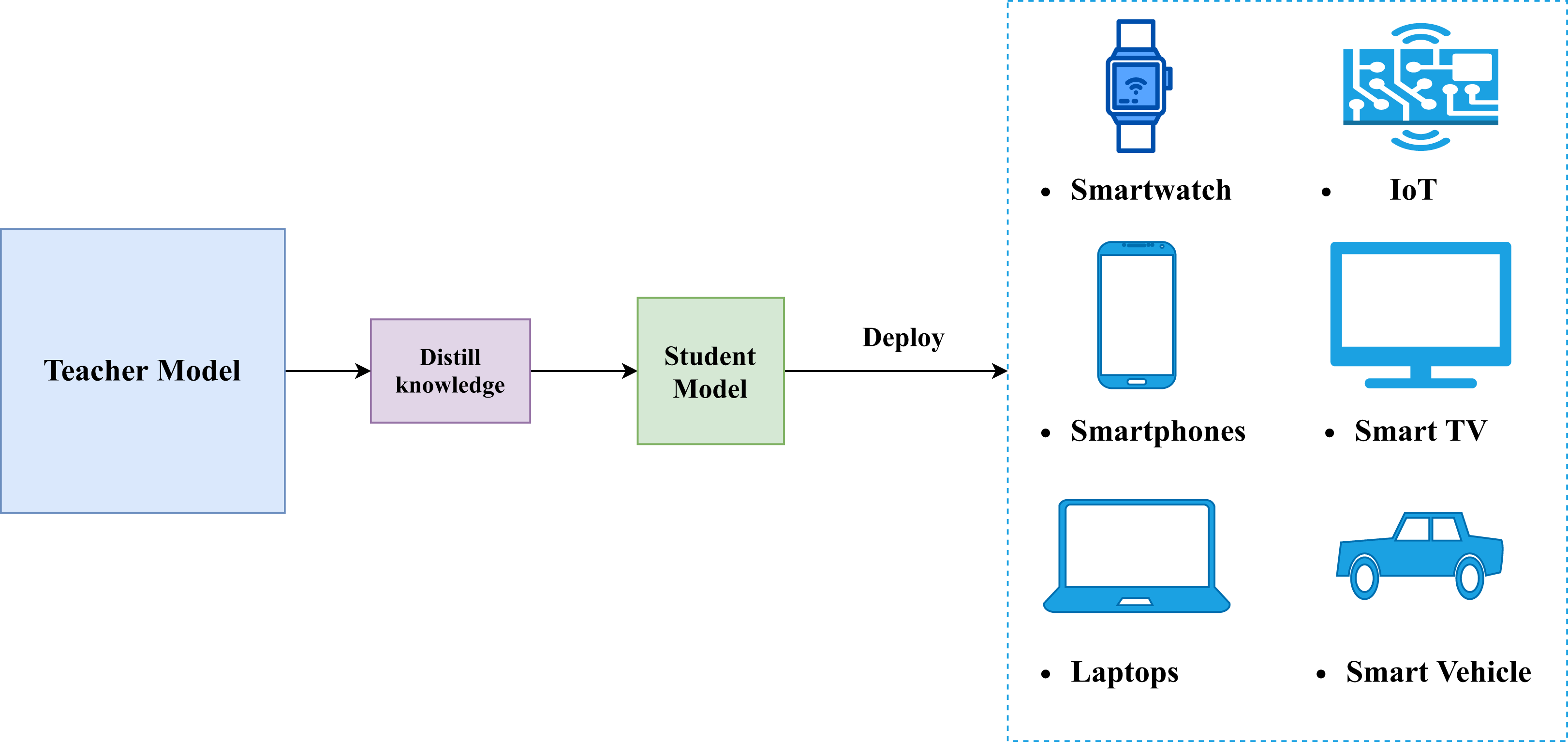
Computational Efficiency: By transferring the knowledge from a larger, more complex model to a smaller model, we can significantly reduce the computational resources and memory requirements of the smaller model, making it more suitable for deployment on edge devices and other resource-constrained environments.
-
Performance Improvement: Knowledge distillation can result in improved performance on unseen data, especially in cases where the student model has a different architecture than the teacher model.
-
Regularization: The process of knowledge distillation can also act as a form of regularization, reducing overfitting and improving the generalization ability of the student model.
Applications of Knowledge Distillation
-
Compression of Deep Neural Networks: Knowledge distillation can be used to reduce the size of deep neural networks, making them more suitable for deployment on resource-constrained devices.
-
Transfer Learning: Knowledge distillation can also be used as a form of transfer learning, allowing a pre-trained model to be fine-tuned for a specific task with a smaller, more computationally efficient model.
-
Ensemble Methods: Knowledge distillation can be used to combine the predictions of multiple models, resulting in a more robust and accurate model.
Implementing Knowledge Distillation in Code
Here is a code snippet in PyTorch to demonstrate the implementation of knowledge distillation:
import torch
import torch.nn as nn
class DistillationLoss(nn.Module):
def __init__(self, temperature):
super(DistillationLoss, self).__init__()
self.temperature = temperature
def forward(self, log_softmax_outputs, targets):
loss = nn.KLDivLoss()(nn.LogSoftmax(dim=1)(log_softmax_outputs/self.temperature), targets)
return loss
# define the student model and the teacher model
student_model = ...
teacher_model = ...
# set the temperature for the distillation loss
temperature = ...
# set the optimizer for the student model
optimizer = ...
# define the distillation loss
criterion = DistillationLoss(temperature)
# training loop
for epoch in range(num_epochs):
for inputs, labels in train_loader:
optimizer.zero_grad()
student_outputs = student_model(inputs)
teacher_outputs = teacher_model(inputs)
targets = nn.Softmax(dim=1)(teacher_outputs/temperature)
loss = criterion(student_outputs, targets)
loss.backward()
optimizer.step()
Conclusion
Knowledge distillation is a powerful technique for transferring the knowledge from a large, more complex model to a smaller, more computationally efficient model. It has numerous applications, including compression of deep neural networks, transfer learning, and ensemble methods. The implementation of knowledge distillation is straightforward, with a number of well-documented techniques and code snippets available to help with the implementation.
Share on
Twitter Facebook LinkedInComments are configured with provider: facebook, but are disabled in non-production environments.
