
Introduction
The Meta Llama 3.1 is a collection of pretrained and instruction tuned generative models in 8B, 70B and 405B sizes (text in/text out).
Model Release Date: July 23, 2024.
When it comes to loading and fine-tuning LLMs using various tools and libraries. Hugging Face, with its extensive API, offers multiple methods to load and interact with these LLMs, each tailored to different needs. However, this flexibility can also be confusing.
Using Hugging Face’s Pipelines
This is the simplest and easiest way when you need to get up and running with LLaMA 3.1 as quickly as possible, Hugging Face’s pipeline API is your go-to. This method abstracts away most of the complexity, allowing you to focus on the task at hand, whether it’s text generation, sentiment analysis, or translation.
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3.1-8B"
pipeline = transformers.pipeline(
"text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto"
)
pipeline("The reason why bigbang happend is")
Loading checkpoint shards: 100%|██████████| 4/4 [00:01<00:00, 2.95it/s],
"[{'generated_text': 'The reason why bigbang happend is because of the big bang theory. The big bang theory is a theory that explains the origin of the universe. The theory was first proposed by the Belgian priest Georges Lemaître in the 1920s. The big bang theory is based on the idea that the universe began as a small, hot, dense point and then expanded and cooled to form the universe we see today.\\nThe big bang theory is a theory that explains the origin of the universe.'}]"
The pipeline API automatically handles model loading, tokenization, and inference, making it ideal for developers who need results fast without diving into the nitty-gritty details of model configuration.
Class Used: transformers.pipeline
Ideal For: Quick prototyping, minimal setup, and rapid testing.
Limitations: Limited flexibility in customizing model behavior. Not suited for fine-tuning or large-scale training.
HuggingFace will automatically download the model weights and everything necessary,
the model weights are usually stored in ~/.cache/huggingface/hub/ directory.
Using AutoModelForCausalLM:
When it comes to fine-tuning a pre-trained model like LLaMA 3.1, the AutoModelForCausalLM class from Hugging Face can be regarded as a good choice. This class is designed to handle causal language models, and it makes the process of loading and configuring the model straightforward. One of the key advantages of using AutoModelForCausalLM is that it automatically reads the model’s JSON configuration file, setting up the architecture based on the parameters defined during pre-training.
Why Use AutoModelForCausalLM for Fine-Tuning?
- Automatic Configuration: Hugging Face’s
AutoModelForCausalLMautomatically loads the model’s architecture from the JSON configuration. This means you don’t have to manually specify the model’s layers, attention heads, or other parameters; it’s all taken care of for you. - Flexibility for Fine-Tuning: Since the model is loaded with all its pre-trained parameters intact, you can easily fine-tune it on new data with minimal changes. This makes it a great choice when you need to adapt LLaMA 3.1 to a specific task or domain.
Example of Loading with AutoModelForCausalLM
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "meta-llama/Meta-Llama-3.1-8B"
model = AutoModelForCausalLM.from_pretrained(model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Preparing input text for fine-tuning
input_text = "Fine-tuning LLaMA on new data is straightforward with AutoModelForCausalLM."
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
# Model is now ready for fine-tuning
This model is now ready for fine-tuning on new data. The AutoModelForCausalLM class has loaded the pre-trained LLaMA 3.1 model with the specified configuration, and the tokenizer is set up to process input text for inference or fine-tuning. One can write their own training loop utilizing packages like PEFT and accelerate for efficient model training and fine-tuning.
Quantized Loading with AutoModelForCausalLM and BitsAndBytes: Efficient Inference
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
model_id = "meta-llama/Meta-Llama-3.1-8B"
quant_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quant_config,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
`low_cpu_mem_usage` was None, now set to True since model is quantized.
Loading checkpoint shards: 100%|██████████| 4/4 [00:03<00:00, 1.11it/s]
We can print the model architecture.
print(model)
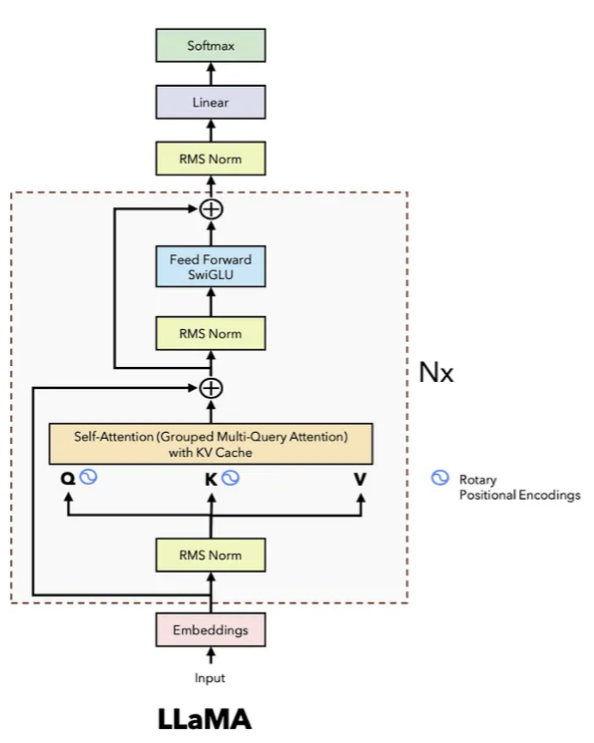
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(128256, 4096)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaFlashAttention2(
(q_proj): Linear8bitLt(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear8bitLt(in_features=4096, out_features=1024, bias=False)
(v_proj): Linear8bitLt(in_features=4096, out_features=1024, bias=False)
(o_proj): Linear8bitLt(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear8bitLt(in_features=4096, out_features=14336, bias=False)
(up_proj): Linear8bitLt(in_features=4096, out_features=14336, bias=False)
(down_proj): Linear8bitLt(in_features=14336, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm((4096,), eps=1e-05)
(post_attention_layernorm): LlamaRMSNorm((4096,), eps=1e-05)
)
)
(norm): LlamaRMSNorm((4096,), eps=1e-05)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=4096, out_features=128256, bias=False)
)
For running inference with the quantized model, we can use the similar code as before.:
input_text = "The reason why bigbang happend is "
tokenizer = AutoTokenizer.from_pretrained(model_id)
model.generation_config.pad_token_id = tokenizer.pad_token_id
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to(model.device)
output = model.generate(input_ids, max_length=100,pad_token_id=tokenizer.eos_token_id, do_sample=True, top_k=50, top_p=0.95)
print(tokenizer.decode(output[0], skip_special_tokens=True))
The reason why bigbang happend is 1. gravity 2. mass 3. energy 4. light 5. space 6. time 7. matter 8. dark matter 9. dark energy 10. space-time 11. mass-energy 12. mass-energy-time 13. mass-energy-time-space 14. mass-energy-time-space-dark matter 15. mass-energy-time-space-dark matter-dark energy 16. mass-energy-time-space-dark matter-dark
you can read the documentations for more details on the generate method and its parameters.
Since we are using the pre-trained LLama 3.1 which was not fine-tuned for anything specific, the output might not be coherent or relevant to the input text.
The quantized model is now ready for efficient inference with reduced memory usage and faster execution times.
Loading LLama with local weights:
If you have model weight available locally, for example you downloaded the orignal .pth file from the Meta repo for LLama 3.1 and converted them into Hugging face weights locally and would like to load from there. Then you can use the from_pretrained method with the local_files_only parameter set to True. This will ensure that the model is loaded from the local directory and not downloaded from the Hugging Face model hub.
local_model_path = "~/.cache/huggingface/hub/DirectorytoModelWeights"
local_model = AutoModelForCausalLM.from_pretrained(local_model_path,
local_files_only=True,
torch_dtype=torch.bfloat16,)
Using LlamaConfig and LlamaForCausalLM:
LlamaConfig is a configuration class that allows you to define the architecture and parameters of the LLaMA model before loading it. This class gives you the flexibility to customize aspects like the number of layers, attention heads, and more.
Why Use It? Customization: Allows for tailored model architectures and hyperparameters. Research and Experimentation: Ideal for exploring different model configurations. Adding enhancement or modifications to the model architecture.
The famous example of using LlamaConfig is the the repo YARN where authors loaded LLama model with LlamaConfig and LlamaForCausalLM with pretrained weights and changed the RoPe (Rotary Positional Embeddings) with their proposed YARN (Yet Another Rotary Positional Embedding) to improve the context window of the model.
from transformers import LlamaConfig, LlamaForCausalLM,AutoTokenizer
import torch
params= {
"attention_bias": False,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": 128001,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 14336,
"max_position_embeddings": 131072,
"mlp_bias": False,
"model_type": "llama",
"num_attention_heads": 16, # 32->16
"num_hidden_layers": 16, # 32->16
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": {
"factor": 8.0,
"low_freq_factor": 1.0,
"high_freq_factor": 4.0,
"original_max_position_embeddings": 8192,
"rope_type": "llama3"
},
"rope_theta": 500000.0,
"tie_word_embeddings": False,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.0.dev0",
"use_cache": True,
"vocab_size": 128256
}
congig_cls = LlamaConfig
model_cls = LlamaForCausalLM
config = congig_cls(**params)
model = model_cls(config)
print(model)
local_model_path = "/home/snawar/.cache/huggingface/hub/models--meta-llama--Meta-Llama-3.1-8B/snapshots/48d6d0fc4e02fb1269b36940650a1b7233035cbb"
model = model.from_pretrained(local_model_path,
local_files_only=True,
torch_dtype=torch.bfloat16,).to('cuda')
model_id = "meta-llama/Meta-Llama-3.1-8B"
input_text = "The reason why bigbang happend is "
tokenizer = AutoTokenizer.from_pretrained(model_id)
model.generation_config.pad_token_id = tokenizer.pad_token_id
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to(model.device)
output = model.generate(input_ids, max_length=100,pad_token_id=tokenizer.eos_token_id, do_sample=True, top_k=50, top_p=0.95)
print(tokenizer.decode(output[0], skip_special_tokens=True))
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 24.87it/s]
The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
The reason why bigbang happend is 2nd law of thermodynamics.
2nd law of thermodynamics is entropy increase.
Entropy is probability of disorder.
So, there is always probability of disorder.
But, there is no probability of order.
That is, the probability of order is 0.
So, entropy can be 0.
And, when entropy is 0, temperature is infinite.
Infinite temperature is infinite energy.
So, the universe will have infinite energy.
And,
Even though i changed the num_hidden_layers and num_attention_heads in the param from 32 to 16 , The model weights were still loaded.
Meta’s Original Implementation: The Full LLaMA Experience
Meta’s original implementation offers the most control, particularly for large-scale distributed training. The original LLama 3.1 architecture is purely implemented in PyTorch.
import torch.distributed as dist
from fairscale.nn.model_parallel.initialize import initialize_model_parallel, get_model_parallel_world_size
from models.llama3_1.api.args import ModelArgs
from models.llama3_1.reference_impl.model import Transformer
import os
import torch.distributed as dist
# Set environment variables manually if not running in a distributed launcher
os.environ['RANK'] = '0'
os.environ['WORLD_SIZE'] = '1'
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '9300'
# Continue with the rest of the script...
# Initialize the PyTorch distributed environment
dist.init_process_group(backend='nccl', rank=0, world_size=1)
# Initialize the model parallel group
initialize_model_parallel(model_parallel_size_=1)
# Define your configuration
json = {
"dim": 4096,
"ffn_dim_multiplier": 1.3,
"multiple_of": 1024,
"n_heads": 32,
"n_kv_heads": 8,
"n_layers": 32,
"norm_eps": 1e-05,
"rope_theta": 500000.0,
"use_scaled_rope": True,
"vocab_size": 128256
}
config = ModelArgs
param = config(**json)
# Initialize the model
print("loading model ....")
llama_model = Transformer(param)
print(llama_model)
# load the .pth model weigths with model.load_state_dict(torch.load("path/to/your/model.pth"))
# Now you can proceed with your training or inference tasks
This method is geared towards advanced users who are comfortable managing distributed systems and need to train or fine-tune LLaMA 3.1 at scale.
The repo for LLama 3.1 itself does not contain the scripts for traning, finetuning and inference but there is a separate repo for that called llama-recipies which containes several useful scripts.
Why Use It?
Full Control: Best for complex setups requiring model parallelism and distributed training.
Large-Scale Training: Ideal for scenarios where you need to fully leverage your hardware resources.
